Machine Learning coding is considered to be the easiest of all coding landscapes whether you choose Python, Java, or R . We are aggressively moving to the era of minimum coding with maximum efficiency where we have tons of endpoints, APIs, microservices, cloud services, etc. are available. Engineers are more poised into connecting built-out business components (features/microservices) than create anything new. Overall time to market is exceedingly improving to seconds with the augmentation of CI/CD pipeline, containers, K8S(Kubernetes) orchestration, service mesh technologies e.g., Amazon pushes code almost every 12 seconds on an average. The effort going into coding is becoming less however coding remains the brain of any IT system. In the Data Science space, EDA (Exploratory Data Analytics), statistical modeling, data visualization, data engineering (pre-processing), narration (story-telling), etc. takes almost 70-80% of effort whereas coding and deployment (leveraging CI/CD pipeline) take the rest. Business leaders, engineering managers et all have started getting hands-on primarily in cloud engineering, ML model development, automation scripting, etc. to appreciate first-hand value. POC (Proof of Concept) is becoming quite an easy step these days to test the water or to create a business case before we go full-blown investment. Thanks to tons of services and tools to make such PoC such an easy-going endeavor. This article is about drawing sentiments score on certain topics from Twitter social networking media with less effort on coding amid available services, packages, and tools.
Problem statement: 2021 UN Climate Change Conference event COP26 has been held in Glasgow, Scotland, UK. Analyze sentiments of people on this topic relative to the effectiveness of the summit.
Resources used: Jupyter Notebook as an IDE, Tweeter API v1.1, NLTK, Tweepy and TextBlob library and Python 3.8
 Approach: My objective here is to create a PoC for “Sentiment Analysis about Climate Summit effectiveness – COP26 Summit Model” while adopting a “minimal coding with maximum efficiency” approach. We take tweets from Twitter by querying text like “COP26”, storing in a file and data frame, calling NLTK/TextBlob package/method to score sentiments against each text, and finally display relevant output. The output should provide a reasonable indication (at minimum qualitatively) to pull off a full-blown ML model investment. Let’s dive into making stage 1 analytics.
Approach: My objective here is to create a PoC for “Sentiment Analysis about Climate Summit effectiveness – COP26 Summit Model” while adopting a “minimal coding with maximum efficiency” approach. We take tweets from Twitter by querying text like “COP26”, storing in a file and data frame, calling NLTK/TextBlob package/method to score sentiments against each text, and finally display relevant output. The output should provide a reasonable indication (at minimum qualitatively) to pull off a full-blown ML model investment. Let’s dive into making stage 1 analytics.
Step 1. Create App in Twitter and save API key and secret code for later use following steps below:-
- Create Twitter Application Development Account (If doesn’t exist already)
- Create an App in the same account (You give a name to APP under project name)
- Store all credentials such as API Key, Secret code, Bearer Token etc. (Tokens & Keys are generated from the previous step)
- Test some of Twitter API end points (from its LAB with V2 versions which is still evolving). such as “Recent Search” e.g. you can use “cURL” command as below or use postman RESTful service.
- $ curl –request GET “https://api.twitter.com/2/tweets/search/recent?query=from:<your Twitter handle>” –header “Authorization: Bearer <your saved BEARER TOKEN>
Bearer Token will look something like this …
“AAAAAAAAAAAAAAAAAAAAxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxFADAKKKHGFXXXXXXxxxxxxxxxxxxxxxxxxxxxXXXXXXXXXXXXXXXX”
The above cURL command gets your output as a string in JSON format with the respective tweet message that you have tweeted in the last 7 days.
Another tweet API test…
$ curl –request GET –url “https://api.twitter.com/2/tweets?ids=<enter some Twitter id >–header “Authorization:Bearer <Enter Bearer Token>
Here twitter id is the numeric value you see on the browser after we click any message on twitter.com, ex. https://twitter.com/xxxxxxxxxxxxx/status/1457686744816447492 (the highlighted number is the Twitter id , I have scrubbed user id with “xxx…x”)
Step 2: Coding in Jupyter Notebook or any IDE that support Python 3.6..and above
Note: (I have taken a screenshot below from my Jupyter Notebook)

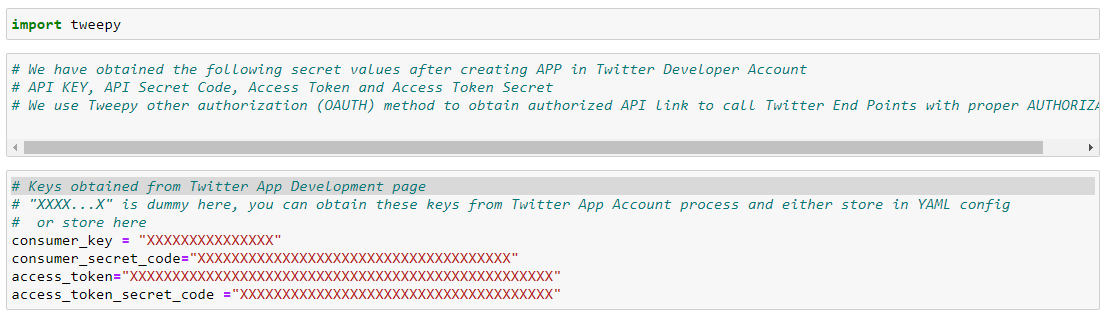
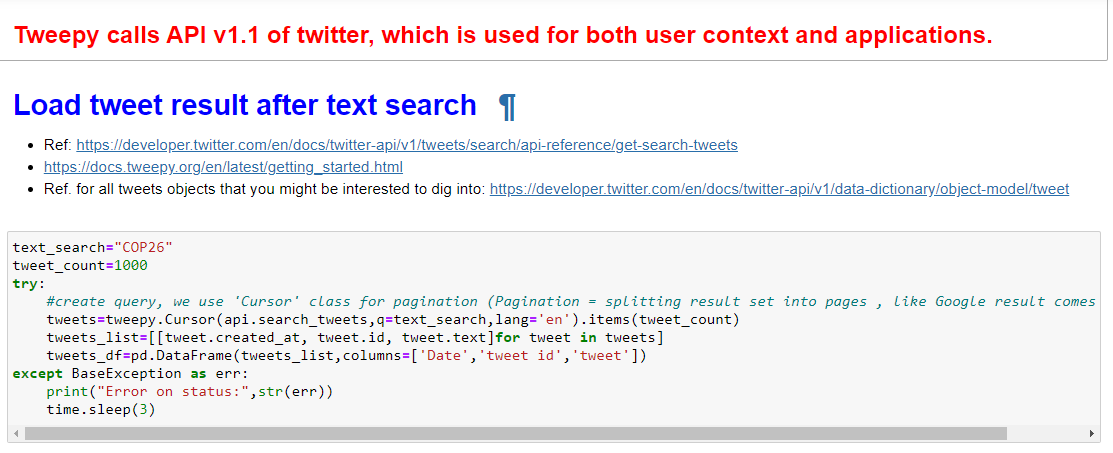
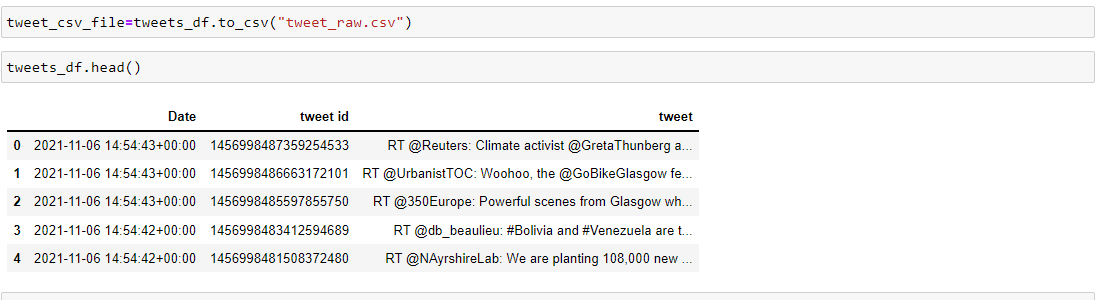
Check tweets with extreme sentiment values. TextBlob reads each sentence and outputs sentiments score between -1 to +1 as negative to positive sentiments:-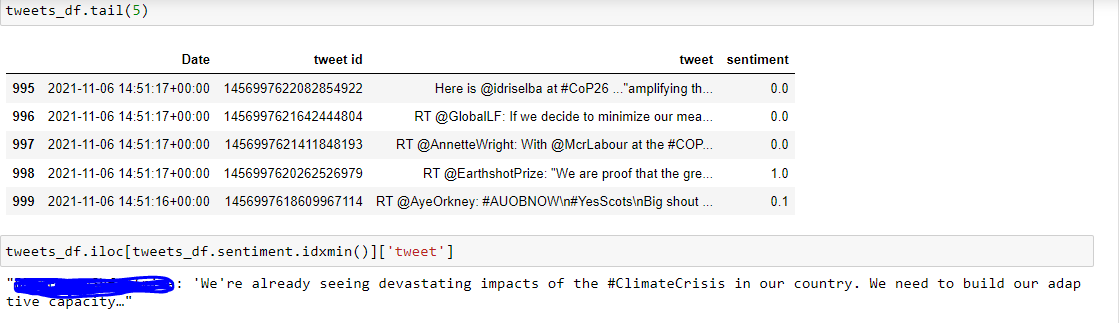
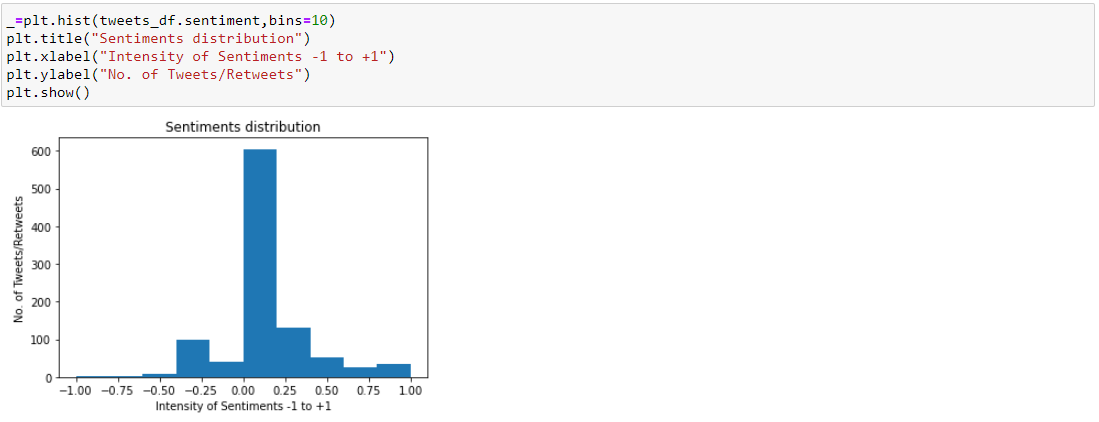
Summary: Sentiment analysis about COP26 summit doesn’t end here, we have just scratched the surface from an analysis standpoint. There are various other dimensions that I didn’t capture here such as views about COP26 summit across countries, demography, occupations, communities, etc. Twitter captures tons of metadata (e.g., location, time, followers, likes, retweets, etc.) while we tweet. We can further enhance the level of analysis by adding business, political, time-series context to name a few. The main purpose is to highlight ease and speed in completing ML PoC to take further business decisions without putting much effort into coding and building expensive data pipelines. Hope you find this approach useful in applying in the journey of digital transformation by creating small use cases or POC solutions before going full-blown in product development.